
Right, onto the final part of my blog articles on our Network Operations Centre, which is Part 3. If you haven’t read the previous articles yet, there’s Part 1 which gives an overview of the whole system and Part 2 which covers the Android sticks. Some if this article will assume that you’ve previously read the other two articles, so please take the time to have a quick read.
In this article, I’ll be covering some of the details of the metric and log collection. As outlined in the first guide, we use a combination of:
- PRTG
- Graphite
- Graphana
- RabbitMQ
- Elasticsearch
- Logstash
- Kibana
- Panopta
General Monitoring
While it may seem like a large list of tools and programs, each covers some very specific use cases. We use PRTG to provide our overall system health, with nearly 1000 sensors monitoring all of our systems. This is a very comprehensive system which can cover deep down into the application layer as well as being very reliable. In our case, we use it to monitor all of our main hardware nodes, dedicated servers for clients and networking infrastructure. For our VPS’s we have our own system for metrics and monitoring, which is detailed further on in this article.
We then use Panopta for external monitoring, so that we have independent data as well as regional specific checks so that we can rule out false positives. Australia’s connectivity to the rest of the world can be choked at times, which results in packet loss. Other alerting systems don’t have a Point of Presence (POP) in Australia, which would result in false positive “outage” alerts. 99% of our market is aimed at and located in Australia, so although a brief international connectivity issue isn’t great, it’s also non-critical. Thankfully, Panopta have 4 POP’s in Australia which means we don’t get woken at 2am anymore for false positives!
As both systems are essentially “out of the box”, there’s not a lot that we customise. PRTG we simply setup custom maps (not the geographic type) to display on our NOC screens but otherwise it simply just runs.
Detailed Logging
For anyone who’s job involves reading logs or analysing logs, the ELK stack (Elasticsearch / Logstash / Kibana) is one set of tools which you’ll want to give a go. Here’s a quick overview of the components:
- Elasticsearch is essentially your logging and search system, which uses JSON data for storage. This is perfect for logs and the search speed is very impressive.
- Logstash does the collection and has plenty of options for reading files as well as many other systems and then has a variety of options to process the data and forward to external systems (like Elasticsearch).
- Kibana is a pure HTML / JS web interface which talks to your Elasticsearch server. This is where you can configure displays with a number of different graphs, widgets and log views.
Since the installation is covered well here, I won’t go into detail within this blog. As long as you have a working Java installation, the installation is quite trivial. Just be sure to allow plenty of storage, memory and processing if you want to index large volumes of logs or at least have the capacity to increase these resources.
We also use Curator to clean up the indices based on set time frames. As logging a lot of data can result in hundreds of gigabytes of data, this is a crucial one to implement. Depending on the type of log, you can set different retention periods or simply set a global one. For example, if you only wanted to hold the indices for 30 days, you could use Curator like this:
curator delete --older-than 30
This will simply clear all indices older than 30 days. There are other options available, make sure you check the documentation.
Fortigate Logging
One of the first items we wanted to be able to see detail logging data on was the Intrusion Prevention System (IPS) for our Fortigate firewalls. While Fortigate have a basic dashboard in which to view the data, we wanted to take it much further and generate custom views based on our exact requirements.
With events like Heartbleed and ShellShock, we were able to create specific dashboards to filter and view only this data related to that event. This way, we were able see the size of the threat as well as ensuring the firewalls were blocking it.
The first step is to collect the logs. The easiest way is to have the Fortigate units forward their data via the standard Syslog format. Fortigate have a handy guide on their log format here, and you’ll certainly need it! Our logging has progressed from the 5.0 format through to the 5.2 log format and while Fortinet claim they’ve standardised the logging more with the 5.2 release, it’s still very fiddly. The examples below will be for 5.2, however there are links to gists for the 5.0 format as well.
Here’s how our system is currently running:
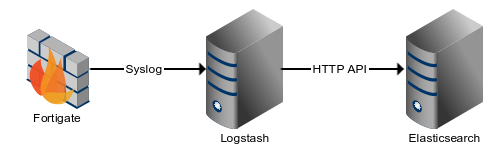
The first step was to configure the Fortigates. Here’s the Syslog format:
config log syslogd setting
set status enable
set server "192.168.xxx.xxx"
set port 514
end
config log syslogd filter
set severity error
end
One thing to note is that the log level is set to error. The reason for this is that by default, the Fortigate systems will log all sessions via syslog and this will result in a significant amount of data. Storing session data in Elasticsearch was generating hundreds of gigabytes a week and taking a considerable amount of resources to do so. For now, we’re simply using the NetFlow data through other software to conduct IP accounting and detailed network analysis.
On the Logstash server, there are two elements to the configuration. The first is the overall config:
filter {
if [type] == "syslog" {
grok {
patterns_dir => ["/etc/logstash/patterns/"]
match => ["message" , "%{FORTIGATE_52BASE} %{FORTIGATE_52IPS}"]
add_tag => ["fortigate"]
}
grok {
patterns_dir => ["/etc/logstash/patterns/"]
match => ["message" , "%{FORTIGATE_52BASEV2} %{FORTIGATE_52DOS}"]
}
}
output {
elasticsearch_http {
host => "IP of the Elasticsearch Server"
}
}
Essentially, this is a fairly vanilla Logstash file. Most of the work is done in the log patterns. This is in a grok format, which takes a bit of getting used to but if you’ve worked with regular expressions before then this is very close. These patterns turn unstructured data into structured data so that it can be easily logged and therefore queried.
I found a few other references where others had used Logstash to log the Fortigate data, however none of them worked perfectly for me. Rather than stopping and starting Logstash to debug getting the patterns to work, there’s a handy Grok Debugger online, which is immensely helpful when first getting started.
With a few hours of fiddling, I managed to get a working solution:
FORTIDATE %{YEAR:year}-%{MONTHNUM:month}-%{MONTHDAY:day}
FORTIGATE_52BASE <%{NUMBER:syslog_index}>date=%{FORTIDATE:date} time=%{TIME:time} devname=%{HOST:hostname} devid=%{HOST:devid} logid=%{NUMBER:logid} type=%{WORD:type} subtype=%{WORD:subtype} eventtype=%{WORD:eventtype} level=%{WORD:level} vd="%{WORD:vdom}"
FORTIGATE_52BASEV2 <%{NUMBER:syslog_index}>date=%{FORTIDATE:date} time=%{TIME:time} devname=%{HOST:hostname} devid=%{HOST:devid} logid=%{NUMBER:logid} type=%{WORD:type} subtype=%{WORD:subtype} level=%{WORD:level} vd="%{WORD:vdom}"
FORTIGATE_52IPS severity=%{WORD:severity} srcip=%{IP:srcip} dstip=%{IP:dstip} sessionid=%{NUMBER:sessionid} action=%{DATA:action} proto=%{NUMBER:proto} service=%{DATA:service} attack="%{DATA:attack}" srcport=%{NUMBER:srcport} dstport=%{NUMBER:dstport} attackid=%{NUMBER:attackid} profile="%{DATA:profile}" ref="%{DATA:ref}";? incidentserialno=%{NUMBER:incidentserialno} msg="%{GREEDYDATA:msg}"
FORTIGATE_52DOS severity=%{WORD:severity} srcip=%{IP:srcip} dstip=%{IP:dstip} sessionid=%{NUMBER:sessionid} action=%{DATA:action} proto=%{NUMBER:proto} service=%{DATA:service} srcintf="%{HOST:srcintf}" count=%{NUMBER:count} attack="%{DATA:attack}" srcport=%{NUMBER:srcport} dstport=%{NUMBER:dstport} attackid=%{NUMBER:attackid} profile="%{DATA:profile}" ref="%{DATA:ref}";? msg="%{GREEDYDATA:msg}" crscore=%{NUMBER:crscore} craction=%{NUMBER:craction}
You can quickly get a copy of the patterns , I have the FortiOS 5.2 Gist: here and FortiOS 5.0 Gist here.
Update: After yet another log format change even with an incremental update to 5.2.3, we’ve swapped over to using the kv filter within Logstash. Here’s what we’re using:
kv {
add_tag => ["fortigate"]
}
Many of the problems came from the fact that the log format seems to change just enough to be annoying. Some items are in quotes whereas others aren’t, so this took a further few hours to sort out. Hopefully, anyone who hasn’t tried it yet can benefit from all the fiddling I’ve already had to do!
If I spend a bit more time I could probably combine a few more of the patterns into one, however once I had it working perfectly I didn’t want to touch it.
Apache Logging
We have hundreds of Apache based webservers within our infrastructure and we’ve enabled centralised logging for a few systems so far. Initially, we’re just logging our own systems to help determine any odd patterns but have plans to push this out to all of our systems.
Since the Apache log file format is very well defined and known, Logstash has the grok pattern as a default inclusion. To log the data, we use the following:
if [type] == "apache" {
grok {
type => "apache"
pattern => "%{COMBINEDAPACHELOG}"
}
mutate {
add_field => { "clientreverse" => "%{clientip}" }
}
dns {
reverse => ["clientreverse"]
action => ["replace"]
}
date {
type => "apache"
# Try to pull the timestamp from the 'timestamp' field (parsed above with
# grok). The apache time format looks like: "18/Aug/2011:05:44:34 -0700"
match => [ "timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
While the basic grok matching is very simple, we then do two further manipulations. The first is to add a field via mutate and perform a reverse dns on it. Rather than just seeing the IP, we can now view the reverse DNS as well as the ability to search via it. When looking at traffic anomalies, this becomes quite useful for quickly visualising normal traffic from foreign attacks. We can also use Logstash to do a geographic lookup of the IP to give us per country / city based data and we’ll be implementing this over the next few weeks.
Postfix Logging
Another area we’re collecting data on is logging Postfix data. This is the standard MTA we use on most of our platforms and when you start reading the logs it’s a bit of a mess. For starters, it uses multiple lines for the same event, so you have to be able to handle parsing when all of the data isn’t initially available. The good news is that Logstash already handles some of these events, albeit in a slightly convoluted way.
This is our Logstash config for Postfix:
input {
file {
type => "postfix"
path => "/var/log/maillog"
}
}
filter {
grok {
type => "postfix"
patterns_dir => [ "/etc/logstash/patterns" ]
pattern => [
"%{SYSLOGBASE} %{POSTFIXSMTPDCONNECTS}",
"%{SYSLOGBASE} %{POSTFIXSMTPDACTIONS}",
"%{SYSLOGBASE} %{POSTFIXSMTPDTIMEOUTS}",
"%{SYSLOGBASE} %{POSTFIXSMTPDLOGIN}",
"%{SYSLOGBASE} %{POSTFIXSMTPDCLIENT}",
"%{SYSLOGBASE} %{POSTFIXSMTPRELAY}",
"%{SYSLOGBASE} %{POSTFIXSMTPCONNECT}",
"%{SYSLOGBASE} %{POSTFIXSMTP4XX}",
"%{SYSLOGBASE} %{POSTFIXSMTP5XX}",
"%{SYSLOGBASE} %{POSTFIXSMTPREFUSAL}",
"%{SYSLOGBASE} %{POSTFIXSMTPLOSTCONNECTION}",
"%{SYSLOGBASE} %{POSTFIXSMTPTIMEOUT}",
"%{SYSLOGBASE} %{POSTFIXBOUNCE}",
"%{SYSLOGBASE} %{POSTFIXQMGR}",
"%{SYSLOGBASE} %{POSTFIXCLEANUP}"
]
named_captures_only => true
}
}
Since the patterns are quite complex, I’ve added them as a gist here. These are originally based on the rules from this gist, thankfully someone has already completed most of the hard work!
As any mail administrator / systems administrator knows, diagnosing issues with email is one of the least fun things to do. Especially in the case where there are dozens or even hundreds of mailservers with different configurations, this becomes a real nightmare. When we receive calls about mail not sending, instead of manually parsing logs (which could take 10 minutes or more) we can now run a search within 30 seconds. Further to this, we can create specific views to help diagnose patterns or anomalies so that we can see issues before they become a real problem. The power of nearly indexed data!
Custom Metrics
While PRTG gives us a lot of data which is easily graphed and alerted, we also collect a lot of custom data which we use for looking at trends and other custom alerting. Areas such as our clustered storage performance, SMTP stats and similar data we collect and process with Graphite. This gives us the ability to collect any time series data and easily pull it out for generating graphs or further analysis. The advantage we have is a “zero config” deployment of stat collection, based on our deployment systems and what we can collect off our main compute nodes. This is what drives our Central stats as well as our own internal monitoring.
Here’s what our systems look like:
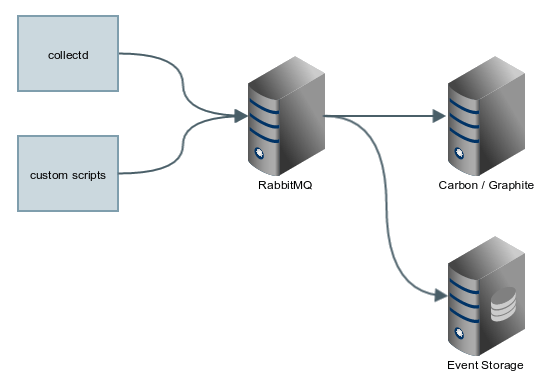
Collectd acts as our statistics collection using some of the built in plugins as well as custom scripts which we’ve written specific for our environment. We use RabbitMQ as a queuing system as it allows us to also divert stats to other systems if we want to store to another database or set custom alerts. The queuing system scales quite well and it’s certainly reliable, so having it as an intermediate system hasn’t degraded the reliability or performance.
Then, have Grafana (based on Kibana) which displays the information in a neat dashboard like manner. This is what we use for our internal monitoring and continually create different dashboards for various monitoring. For those who are used to just using Graphite dashboards, this is a far neater and easier system to configure. It’ll even import your existing dashboards from Graphite, so it’s well worth the few minutes to setup.
Conclusion
This concludes our series on our NOC configuration, hopefully there’s been some useful information for those who are implementing similar systems. Like any monitoring system, nothing stays stagnant so we’ll be constantly updating the displays, logging more data and choosing how we display this data.
There are a myriad of tools out there which can greatly assist with the “big data” problem that exists with any system, no matter what the size. With the ELK stack, you get a comprehensive logging and search system. With Graphite / Grafana, you get a very powerful metrics collection and display system. By utilising both, you can very quickly gain a great insight into your entire platform. Especially if you combine this with an orchestration system such as SaltStack, you can automate the deployment of the data collection and further reduce the administration burden. This is all without having to fork out money for software like Splunk, which at the volumes we log can add significant costs.
If there’s anything you want more detail on or you think I’ve missed, please just add a comment below and I’ll do my best to provide you with the required info!

